
October 2021 | Dios Kurniawan
Organizations are increasingly dependent on data to drive their operations and uncover new opportunities. Over the past several years, data platforms such as data lakes have emerged as strategic enablers for business growth (a data lake is essentially a system for storing a large amount of data in its original raw format). With a data lake, users can produce visualizations, run complex analytics, and build machine learning applications.
Likewise, the current trend leans toward the increased adoption of data democratization within many organizations that makes data more accessible to their employees, even to the non-technical ones. No longer data is monopolized by IT departments or specially trained data analysts. Companies build data lakes, throw raw data into them and provide virtually everyone with access. The term ‘self-service analytics’ has become the norm to help businesses make better and faster decisions, encouraging employees of all levels to analyze data.
However, data democratization is not always backed by data governance which has traditionally lagged behind. With no robust governance and data management, things could get out of hand pretty quickly.
Many organizations fail to establish policies and their enforcement, resulting in multiple redundant copies of data, fragmented data which causes confusion and friction among business units or losing track of what restricted information exists.
In the worst-case scenario, when users keep getting irrelevant information from the data lake, it could easily turn into a data swamp.
Governing The Data
Data governance, at its core elements involves management of security, operations and quality among other things, but central to this is a critical ingredient: metadata management. It is basically the administration of data about data, which helps connect people with data — finding, getting and understanding the data they need.
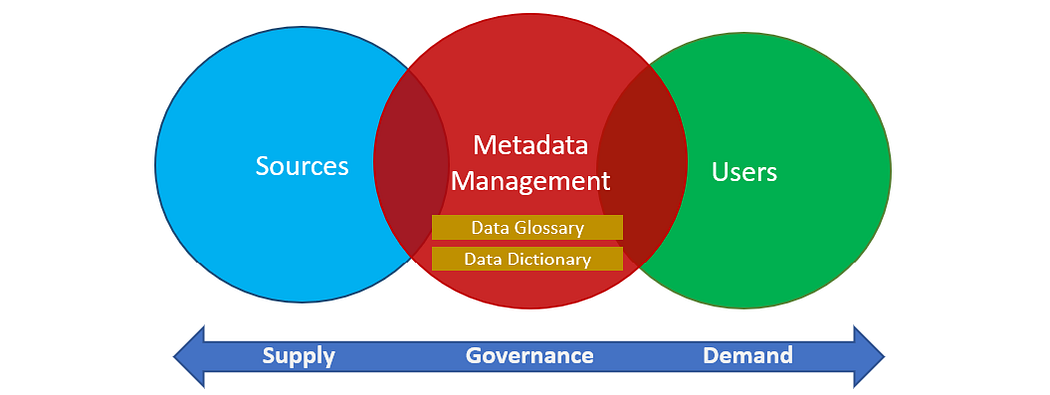
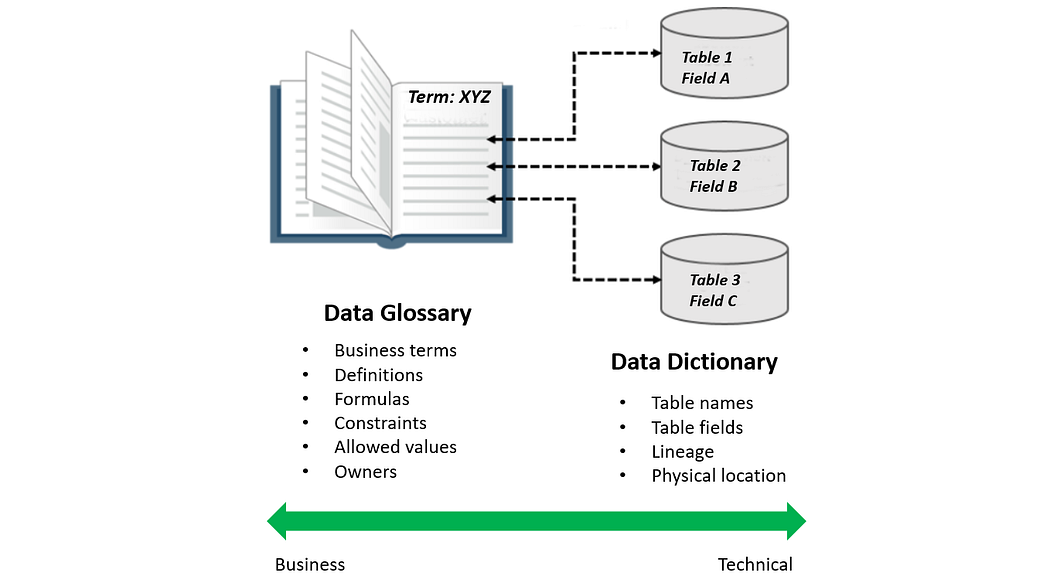
At the minimum, metadata management should include two main components: Data Glossary and Data Dictionary. Data Glossary (or Business Glossary in business settings) serves as a list of common vocabulary along with their meanings and definitions. Like a shopping catalog in a retail store, Data Glossary can be seen as a catalog that describes what pieces of data are available. The artifact also contains information such as categories, ownership, and sensitivity level.
Data Dictionary, on the other hand, contains the technical information on physical data assets. It helps users discover how the data is actually stored in the data lake. An entry in the Data Dictionary represents an instance of physical data (file, table, object, etc). For example, all fields in a table are displayed each with its description, data type, and possible values it contains.
To build relationships between Data Glossary and Data Dictionary, each entry in the Data Glossary is tagged with related entries in the physical data assets.
One of the biggest challenges in metadata management is maintaining the manually curated entries. The knowledge to create a business glossary almost always resides in the minds of highly skilled persons in business units or in IT divisions. Metadata repository can quickly become outdated as people change roles frequently within the company. A set of specialized software tools is needed to overcome this problem.
Metadata Management in Telkomsel Data Platform
Although there are plenty of options for commercial metadata management software in the market, at Telkomsel we opt for a vendor-agnostic approach, that is, built using open-source software. We have gone to great lengths to build our own metadata management system to augment our data lake platform: we name this application MELODY (a play of words for metadata, glossary, and dictionary).

In MELODY, users can “shop” for data with the help of Search Service. It handles search requests from the users, allowing easy lookup of data definitions using keywords. Employees can quickly find the data they need in the data lake.
Below is a sample entry in MELODY where a business term has associated tables with it, providing users with more context of how to obtain the actual data.
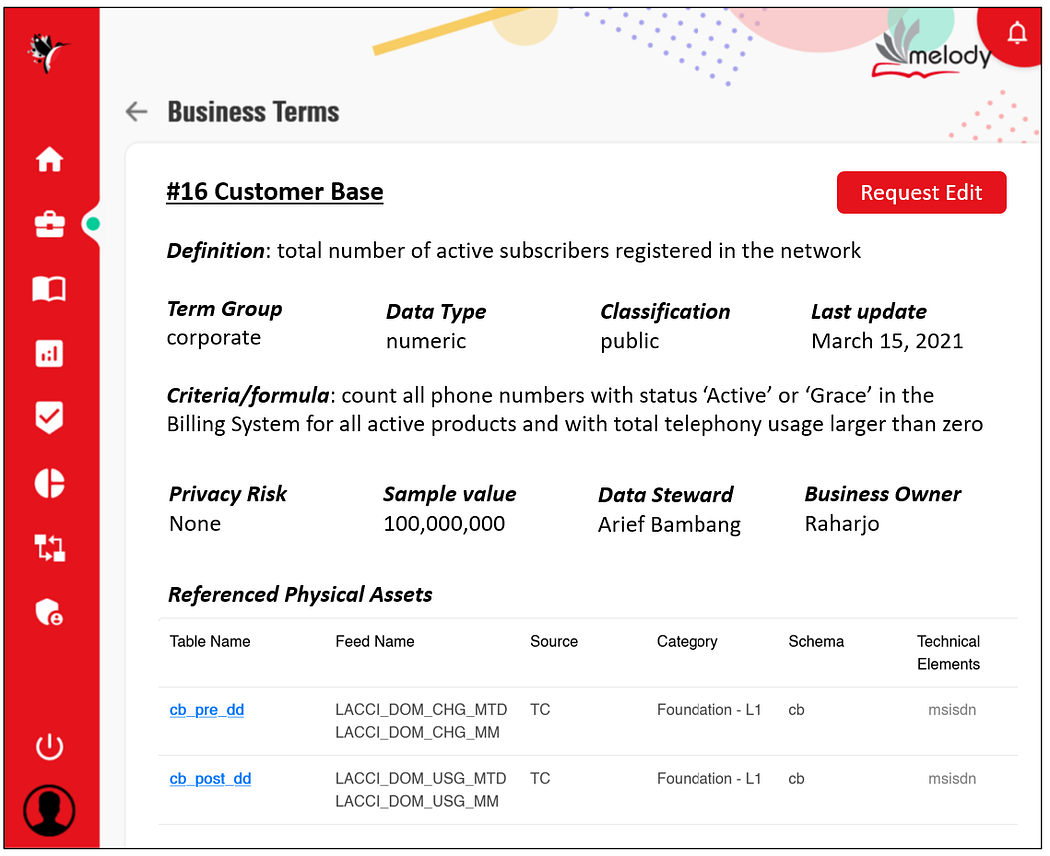
MELODY also shows the category, sensitivity, and privacy risk of each business term to give users an idea of how to handle the asset. Owners in charge of the business terms can also be identified.
As you might have noticed in the picture above, a “Request Edit” button enables users to propose a change to a business concept. This is how MELODY performs crowdsourcing which sparks collaboration among users, allowing up-to-date definitions, rules, and formulas to be made by people who know the matter most. Behind the scene, proposed changes undergo a review and approval process taken by appointed Data Stewards with a purpose to certify the new information.
Data Dictionary gets populated by Metadata Discovery module. It works by extracting metadata information from the data platform. File names, table names, field names, data types along with other statistics are regularly collected by the software and subsequently stored in the Data Dictionary repository. Data lineage is collected as well from transformation processes to understand the origin of each data element, which will be useful for troubleshooting data quality issues.
Integration with Data Quality Management system is created to display quality statistics (you may want to read my post about data quality). Providing data quality information helps gain users’ trust in the data they are about to consume.
MELODY also encompasses Reference Data Management in a single tool. Here, slowly-changing reference data (such as product codes, client codes, etc.) is controlled with versioning and approval workflow.
Tagging each business term in the Data Glossary with the entries in Data Dictionary has to be done manually to create the baseline. However, doing this by hand is not tenable in the long run. One of the solutions is to use Machine Learning Data Catalog (MLDC) technology to perform automated tagging. For example, clustering is employed to group similar data fields, then values inside them are used to train a model which will next recommend a matching business term. Machine Learning can also identify personally identifiable information (PII) in the data.
Key Takeaways for Metadata Management
Democratizing data may sound like a good idea, but finding the right balance between control and freedom is challenging because it requires the establishment of clear governance policies, strong enforcement processes, and the implementation of the right technology.
Data democratization forces organizations to rethink their approach to data governance, in which metadata management plays a crucial role.
Like a library, metadata management bridges the gap between what users perceive about the data with the actual physical data in the data platform. This is particularly true because knowledge of data tends to be possessed only by technical individuals. Good metadata management will foster data literacy and enforce discipline across the board.
With metadata management in place, the following benefits can be achieved:
- Projects can be delivered faster since data analysts, data scientists, and engineers can find the data they need more quickly.
- Breaking down information silos as knowledge of data is accessible by everyone.
- Quality of data can be gradually assured because quality metrics can be clearly monitored on key data.
- Compliance with laws and regulations by correctly categorizing sensitive information.
- Efficient use of computing and storage resources.
Because of its complexity, metadata management may require a great deal of commitment and investment, however, most enterprises are convinced that the costs are justified. As our experience in Telkomsel, building a metadata management system was seen at first as a high-cost initiative with less tangible business value, but along the way as people’s trust in the data improved and resources could be saved by performing things more efficiently, the investment would start to pay off.
